ch14 크롤링 시작하기
💡 이번 차시의 학습목표
✔ 크롤링 실습하기
- 다나와 - 상품목록 크롤링하기
- 네이버웹툰 - 웹툰 제목 크롤링하기
01. 다나와 상품 목록 크롤링하기
- 검색주소값 가져오기
- 다나와 홈페이지 접속
- 검색창에 노트북 입력 후 검색버튼 클릭
- 검색 링크
- 상품명 요소 확인하기
- selenium으로 요소 접근하기
- 상품명은 a 태그의 text 속성 형태로 표현되어 있음.
- 해당 태그에는 class, id와 같은 속성은 없으며, name=productName 속성 있음.
- name 속성을 활용하여 접근
- name속성은 By.CSS_SELECTOR 이용
- 사용문법
- find_elements(By.CSS_SELECTOR, ‘[name=”productName”]’)
- 내용이 여러 개이므로 find_elements 사용
- [ ]부분을 감싸는 ‘(single quote), name값을 감싸는 “(double quote) 주의하여 작성
- 사용문법
- 크롤링 데이터 확인하기
- 상품명 출력을 위해 for 문 활용
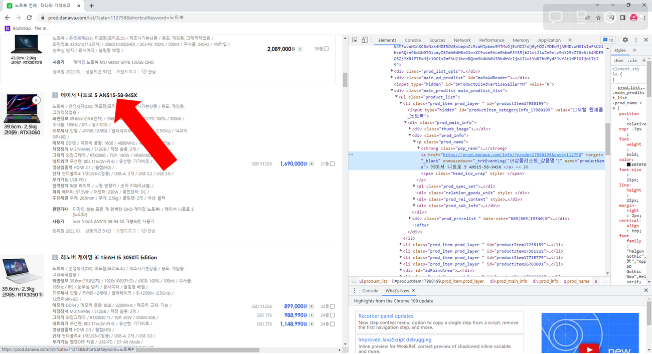
01-1. 실습 예제
📥실습 코드
ex01_crawling.py
from selenium import webdriver
from selenium.webdriver.common.by import By
# 다나와 상품목록 크롤링
# 브라우저 실행
driver = webdriver.Chrome()
# 접속
driver.get("<https://prod.danawa.com/list/?cate=112758&shortcutKeyword=%EB%85%B8%ED%8A%B8%EB%B6%81>")
notebook_names = driver.find_elements(By.CSS_SELECTOR, '[name="productName"]')
# print(notebook_names)
for name in notebook_names:
# 코드값이 보임
# print(name)
# 텍스트 출력하기
print(name.text)
02. 네이버웹툰 웹툰 제목 크롤링하기
- 검색주소값 가져오기
- 네이버웹툰 홈페이지 접속
- 웹툰제목 요소 확인하기
- 전체 웹툰이 보이는 화면에서 월요웹툰 중 첫번째 웹툰의 제목 요소 확인
- 개발자도구 열고 웹툰제목을 표시하는 요소 확인
<a class="ContentTitle__title_area--x24vt" href="/webtoon/list?titleId=648419"> <span class="ContentTitle__title--e3qXt">뷰티풀 군바리</span></a>
selenium으로 요소 접근하기- 웹툰 제목은 a 태그에 표현되어 있고, class=”ContentTitle__title_area--x24vt” 속성을 가지고 있음.
- class=”ContentTitle__title_area--x24vt”로 속성 접근
- class속성은 By.CLASS_NAME 이용
- 사용문법
- find_elements(By.CLASS_NAME, ‘ContentTitle__title_area--x24vt’)
- 내용이 여러 개이므로 find_elements 사용
- 사용문법
- 크롤링 데이터 확인하기
- 웹툰제목 출력을 위해 for 문 활용(웹툰 갯수가 578개로 출력에 1분이상 소요)
02-1. 실습 예제
📥실습 코드
ex02_crawling.py
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("<https://comic.naver.com/webtoon>")
time.sleep(2)
webtoon_titles = driver.find_elements(By.CLASS_NAME, 'ContentTitle__title_area--x24vt')
time.sleep(5)
for name in webtoon_titles:
print(name.text)
print(len(webtoon_titles))
ch15 유튜브 크롤링-시작
💡 이번 차시의 학습목표
✔ 유튜브 홈페이지 구성요소 확인
✔ 유튜브 영상 제목 크롤링 하기
01. 유튜브 홈페이지 구조 살펴보기
- **홈페이지 주소: https://www.youtube.com/
- 크롬 개발자 도구 열어서 영상의 요소 확인
- 요소 선택을 위한 아이콘 클릭
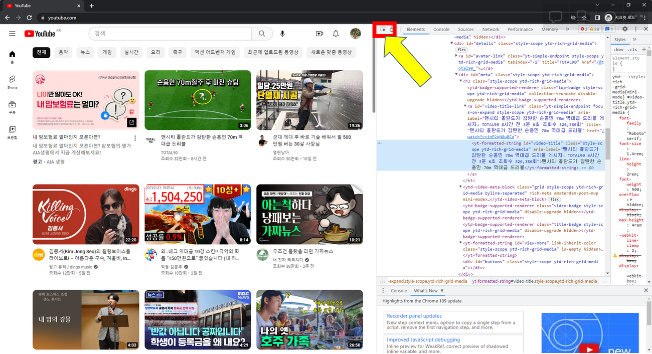
- 유튜브 영상의 제목 부분 클릭하여 요소 확인

- 선택된 부분 마우스 우클릭하여 요소 복사 가능
- 예시에서 복사한 요소
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media" aria-label="54톤 거대 고래 뱃속에서 발견된 것은? [국경없는 영상] 게시자: YTN 2일 전 1분 54초 조회수 1,400,217회">54톤 거대 고래 뱃속에서 발견된 것은? [국경없는 영상]</yt-formatted-string>
- 예시에서 복사한 요소
- 요소 선택을 위한 아이콘 클릭
02. 제목 텍스트 표현 요소 접근하기
- 제목 텍스트 위치 확인
- 영상의 제목은 <yt-formatted-string></yt-formatted-string> 태그 내에 작성되어 있음
- yt- 또는 ytd- 로 시작하는 태그는 사용자 정의 요소(Custom Element)이며, selenium으로 요소를 가져올 때는 id, class 등 html 요소를 주로 이용
- 사용자 정의 요소: 표준 html 요소가 아니며, 특정 디자인이나 기능 등을 반복적으로 사용할 때 활용할 수 있음
- yt- 또는 ytd- 로 시작하는 태그는 사용자 정의 요소(Custom Element)이며, selenium으로 요소를 가져올 때는 id, class 등 html 요소를 주로 이용
- 영상의 제목은 <yt-formatted-string></yt-formatted-string> 태그 내에 작성되어 있음
- 제목 텍스트를 가져오기 위해 id=”video-title” 속성 활용
- selenium의 find_elements() method를 사용하여 전체 내용을 가져옴
titles = driver.find_elements(By.ID, "video-title") - XPATH로도 접근 가능
- “ ”, ‘ ’ 사용 위치 주의
titles = driver.find_elements(By.XPATH, '//*[@id="video-title"]')
- selenium의 find_elements() method를 사용하여 전체 내용을 가져옴
- titles의 자료형 확인
- type 함수 사용하여 가져온 요소의 자료형 확인
print(type(titles)) - list이기 때문에 내용을 확인하기 위해선 반복문을 활용해야 함
- type 함수 사용하여 가져온 요소의 자료형 확인
03. 제목 텍스트 출력하기
- list를 접근하기 위해 for문 활용하여 출력
- text 속성을 사용하여 제목값을 출력할 수 있음
for title in titles: print(title.text) - 태그 이름 출력
print(title.tag_name) - aria-label 속성값 출력
print(title.get_attribute("aria-label")
- text 속성을 사용하여 제목값을 출력할 수 있음
04. 실습 예제
📥실습 코드
ex01_youtube.py
from selenium import webdriver
from selenium.webdriver.common.by import By
# 브라우저 실행
driver = webdriver.Chrome()
driver.get("<https://www.youtube.com/>")
# titles = driver.find_elements(By.ID, "video-title")
titles = driver.find_elements(By.XPATH, '//*[@id="video-title"]')
print(titles)
print(type(titles))
for title in titles:
print(title.tag_name) # 태그 이름 가져오기
print(title.text) # inner HTML 값 가져오기
print(title.get_attribute("aria-label")) # 속성값 가져오기
ch16 유튜브 크롤링-검색 기능 활용
💡 이번 차시의 학습목표
✔ 검색어를 입력하여 검색된 영상의 제목 크롤링 하기
✔ selenium으로 검색창, 검색버튼 사용하기
01. 유튜브 검색 환경 살펴보기
- 유튜브 검색창에 ‘뉴진스’ 입력 후 검색

- 검색과정
1.검색창에 검색어(키워드) 입력 → 🔍검색 버튼 또는 엔터 입력
02. 검색하는 과정 selenium으로 구현해보기
- 과정
- selenium으로 유튜브 홈페이지 접속
- 검색창 요소 접근
- 검색어 입력하기
- 검색 버튼 클릭하기 또는 엔터키 입력
- selenium으로 유튜브 홈페이지 접속
driver.get("https://www.youtube.com/") - 검색어 입력 요소 접근
- 검색어 입력창 요소 확인
- 개발자 도구 열어서 검색어 입력창 클릭

- input 태그이며, id=”search” 속성이 적용되어 있음
<input id="search" autocapitalize="none" autocomplete="off" autocorrect="off" name="search_query" tabindex="0" type="text" spellcheck="false" placeholder="검색" aria-label="검색" role="combobox" aria-haspopup="false" aria-autocomplete="list" class="gsfi ytd-searchbox" dir="ltr" style="border: none; padding: 0px; margin: 0px; height: auto; width: 100%; outline: none;">
- 개발자 도구 열어서 검색어 입력창 클릭
- selenium으로 검색어 입력창 가져오기
- css 선택자로 접근(id=”search” 가 적용된 input 태그)
search_input = driver.find_element(By.CSS_SELECTOR, "input#search")
- css 선택자로 접근(id=”search” 가 적용된 input 태그)
- 검색어 입력창 요소 확인
- 검색어 입력하기
- selenium의 send_keys() method를 이용하여 검색어 입력
search_input.send_keys("뉴진스")
- selenium의 send_keys() method를 이용하여 검색어 입력
- 검색버튼 클릭하기
- 검색버튼 요소 확인
- 개발자도구에서 검색 버튼 요소 확인
<button id="search-icon-legacy" class="style-scope ytd-searchbox" aria-label="검색"> <yt-icon class="style-scope ytd-searchbox"><svg viewBox="0 0 24 24" preserveAspectRatio="xMidYMid meet" focusable="false" class="style-scope yt-icon" style="pointer-events: none; display: block; width: 100%; height: 100%;"><g class="style-scope yt-icon"><path d="M20.87,20.17l-5.59-5.59C16.35,13.35,17,11.75,17,10c0-3.87-3.13-7-7-7s-7,3.13-7,7s3.13,7,7,7c1.75,0,3.35-0.65,4.58-1.71 l5.59,5.59L20.87,20.17z M10,16c-3.31,0-6-2.69-6-6s2.69-6,6-6s6,2.69,6,6S13.31,16,10,16z" class="style-scope yt-icon"></path></g></svg><!--css-build:shady--></yt-icon> <tp-yt-paper-tooltip prefix="" class="style-scope ytd-searchbox" role="tooltip" tabindex="-1" style="left: 815.5px; top: 62px;"><!--css-build:shady--><div id="tooltip" class="style-scope tp-yt-paper-tooltip hidden" style-target="tooltip"> 검색 </div> </tp-yt-paper-tooltip> </button>
- 개발자도구에서 검색 버튼 요소 확인
- selenium으로 검색 버튼 접근
- css 선택자로 접근
search_button = driver.find_element(By.CSS_SELECTOR, "button#search-icon-legacy")
- css 선택자로 접근
- 검색 버튼 클릭하기
search_button.click()
- 검색버튼 요소 확인
- 검색어 입력 후 엔터 입력으로 검색하기
- 검색어 입력까지의 과정은 동일
- 검색어 입력 후 엔터키 입력 동작을 위해 Keys 라이브러리 추가
from selenium.webdriver.common.keys import Keys - 검색어 입력 및 엔터 입력
search_input.send_keys("뉴진스") search_input.send_keys(Keys.RETURN)
ex01_search.py from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time # 브라우저 실행 driver = webdriver.Chrome() driver.get("https://www.youtube.com/") search_input = driver.find_element(By.CSS_SELECTOR, "input#search") # print(search_input.tag_name) search_input.send_keys("뉴진스") # 검색버튼 클릭 search_button = driver.find_element(By.CSS_SELECTOR, "button#search-icon-legacy") search_button.click() time.sleep(2) # 엔터키 입력 # search_input.send_keys(Keys.RETURN) titles = driver.find_elements(By.ID, "video-title") for title in titles: print(title.text)
03. 다른 방법으로 검색 결과 가져오기
- 유튜브 검색 시 브라우저의 주소값 살펴보기
- ‘뉴진스’ 검색하는 경우 주소값
- ‘bts’ 검색하는 경우 주소값
- 주소값 분석
- ‘https://www.youtube.com/results?search_query=’ 부분은 동일하며 search_query=’검색어’ 형태로 검색어에 따라 마지막 부분만 바뀜
- selenium으로 주소값에 검색어를 포함하여 시작
- ‘뉴진스’ 검색결과 페이지로 직접 접속
driver.get("https://www.youtube.com/results?search_query=뉴진스") - 실습코드
ex02_search.py from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("<https://www.youtube.com/results?search_query=뉴진스>") titles = driver.find_elements(By.ID, "video-title") for title in titles: print(title.text)
- ‘뉴진스’ 검색결과 페이지로 직접 접속
- 검색어를 콘솔로 입력받아 적용하기
- input 함수로 입력값 변수로 가져오기(아래 문장이 가장 먼저 실행되어야 함)
q = input("검색어를 입력하세요: ")
검색어를 요청 주소에 추가하기- ‘+’ 를 이용하여 연결
driver.get("<https://www.youtube.com/results?search_query=>"+q)
- ‘+’ 를 이용하여 연결
- 실습코드
ex03_search.py from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys import time q = input("검색어를 입력하세요: ") driver = webdriver.Chrome() driver.get("<https://www.youtube.com/results?search_query=>"+q) titles = driver.find_elements(By.ID, "video-title") for title in titles: print(title.text)
- input 함수로 입력값 변수로 가져오기(아래 문장이 가장 먼저 실행되어야 함)
'Python' 카테고리의 다른 글
| [Python] 판다스 Pandas (1) | 2024.03.21 |
|---|---|
| [Python] 유튜브 크롤링(2) (0) | 2024.03.20 |
| [Python] Selenium 소개 및 사용법 (0) | 2024.03.18 |
| [Python] 패키지 설치 및 numpy, matplotlib 기초 (0) | 2024.03.15 |
| [Python] 함수와 모듈 (0) | 2024.03.11 |